












































随着企业规模的扩大和资料的不断积累,对知识的管理不再是简单的文档存储和查询工具,而是关系到企业运营效率、决策质量和客户服务水平的核心资产。
尤其对于市场、客服中心等每天都在与大量信息打交道的部门,面对海量的客户问题、服务流程和产品知识,很多企业选择知识库作为赋能工具,助力业务运转提效;但实际情况恰恰相反,知识库的管理、运维、应用反而成为企业的难题甚至是负担。
知识库中的“三高”
投入成本高、管理难度高、操作门槛高
▌投入成本高:搭建运维耗时耗力
传统知识库有纯文档知识库和结构化知识库两种类型:纯文档知识库仅支持文件的查询,不能局部修改,应用场景十分有限;而结构化知识库虽然可以进行局部修改,但知识抽取操作复杂,构建和运维都不方便。比如在教育、医疗、金融等行业,由于产品线复杂,各种产品、业务涉及的FAQ就可能多达上万条,人工操作知识抽取需要企业投入大量的人力和时间录入知识,运维成本极高。
▌管理难度高:隔离与共享把控难
企业的部门众多,且每个部门都有自己的知识积累和管理方式,随着业务逐渐增多,知识库中的条目数也会越来越多,知识管理往往会出现混乱,比如多个部门和岗位的人员均可随意编辑和访问,就会导致知识条目被多次重复编辑,导致知识库冗杂、难以管理。另外,企业各个部门本该共享的知识,由于各个知识库之间缺乏联动,形成了信息孤岛,导致信息不对称,业务信息滞后。
传统知识库往往依赖于繁琐的分类结构和静态的文档存储方式,需要花费大量时间翻阅层层文件路径,或通过各种复杂的搜索条件来筛选答案,复杂度操作会让员工和客户对知识库失去信心,从而降低了利用率。
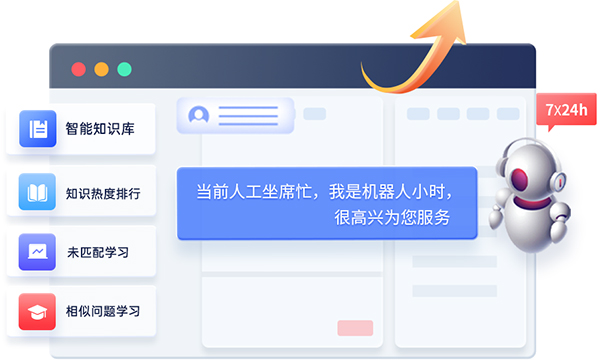
「悦问知识库」降压有方
知识库+大模型新进化
大模型辅助知识导入
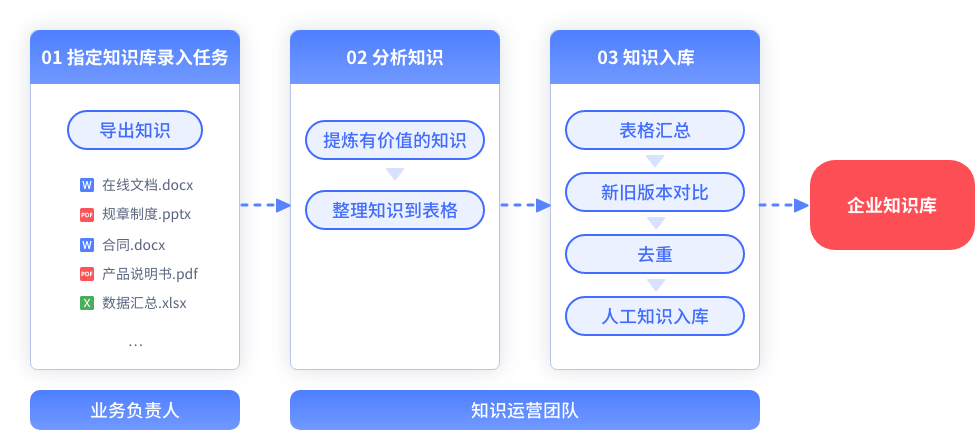
▼悦问知识库录入方式
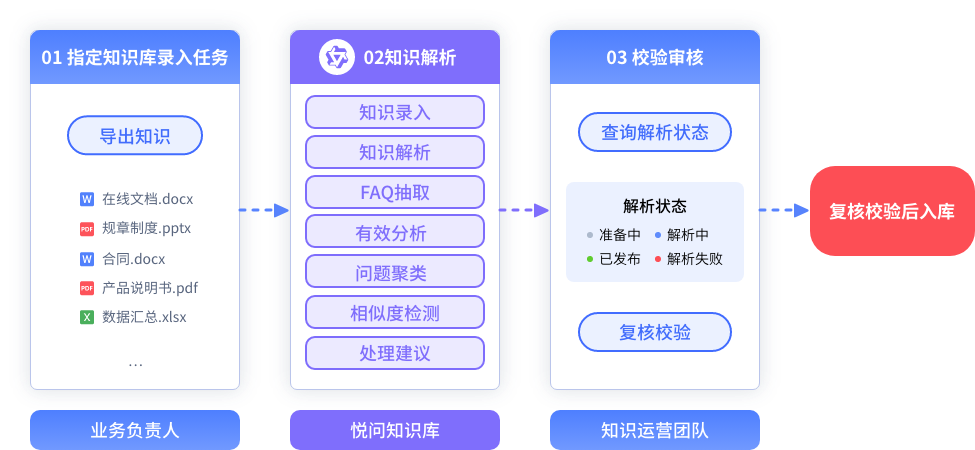
使用悦问知识库后,能把原本需要多部门、安排多名专员耗时2周甚至一个月的工作,缩短到小团队1-3天就能处理完毕,有效降低了企业的搭建和运维成本。
悦问知识库能根据业务情况采用多层级的权限划分,针对不同业务部门需要独立的业务场景时,企业在悦问知识库上传时仅需设定明确的访问、编辑、等操作权限;而需要共享或者公开给客户的资料信息,同样存储在同部门下可公开的层级中,这样就能很好明确知识隔离和共享的权限。

对于可共享的知识资源,用户在搜索时,悦问知识库除了展示所匹配到的知识,还会运用大模型RAG(检索增强生成)技术,从知识库中有检索权限的所有层级类目里匹配与关键词相关的知识源,并将其作为提示(Prompt)输入给大型语言模型(LLM)。这样用户搜索内容获得推荐答案的同时,还有针对性的搜索推荐提示,便于他们查找知识。
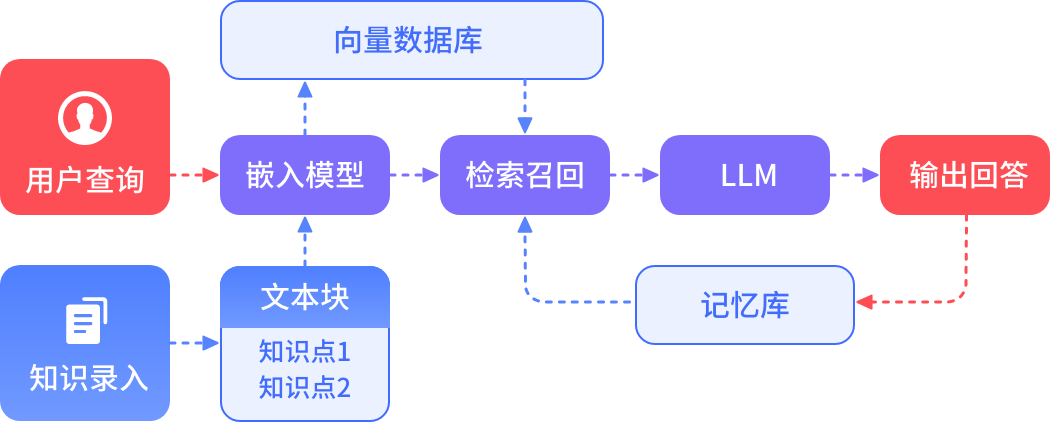
大模型对话式搜索
一步获取精准知识
悦问知识库提供了大模型对话式搜索问答,能去除非知识内容的冗余部分,让使用者能快速匹配到想要快捷且人性化的答案。
在查看知识库文件时,悦问知识库提供右侧的目录直接定位,查看指定内容;左侧导航栏能快速切换至其他已查询到的知识,无需返回或关闭当前页面,减少了用户反复点击的复杂度。

目前悦问知识库的功能和应用场景也在不断优化和扩展,提供包括企业HRSSC、部门知识管理、客服中心的客服辅助、用户自助查询……等全场景的使用,还能同步应用于企业微信、钉钉等第三方IM工具、企业自有系统、合力云客服系统,增强知识库可用性的同时,也降低了企业的运维成本。





 呼叫中心
呼叫中心 在线客服系统
在线客服系统 企微SCRM
企微SCRM AI语音智慧平台
AI语音智慧平台


